Resources / Retrieval Layers
Retrieval Layers
Retrieval layers help readers find source candidates. They do not decide claim status, prove physics, or replace source inspection.
Retrieval is useful when it shortens the path to the owner. It becomes unsafe when the lookup result is treated as the owner.
Static diagram
Keep retrieval layers below canonical source inspection.
The source-first memory diagram shows memory, semantic extracts, mirrors, caches, registries, handoffs, and the final source-inspection boundary.
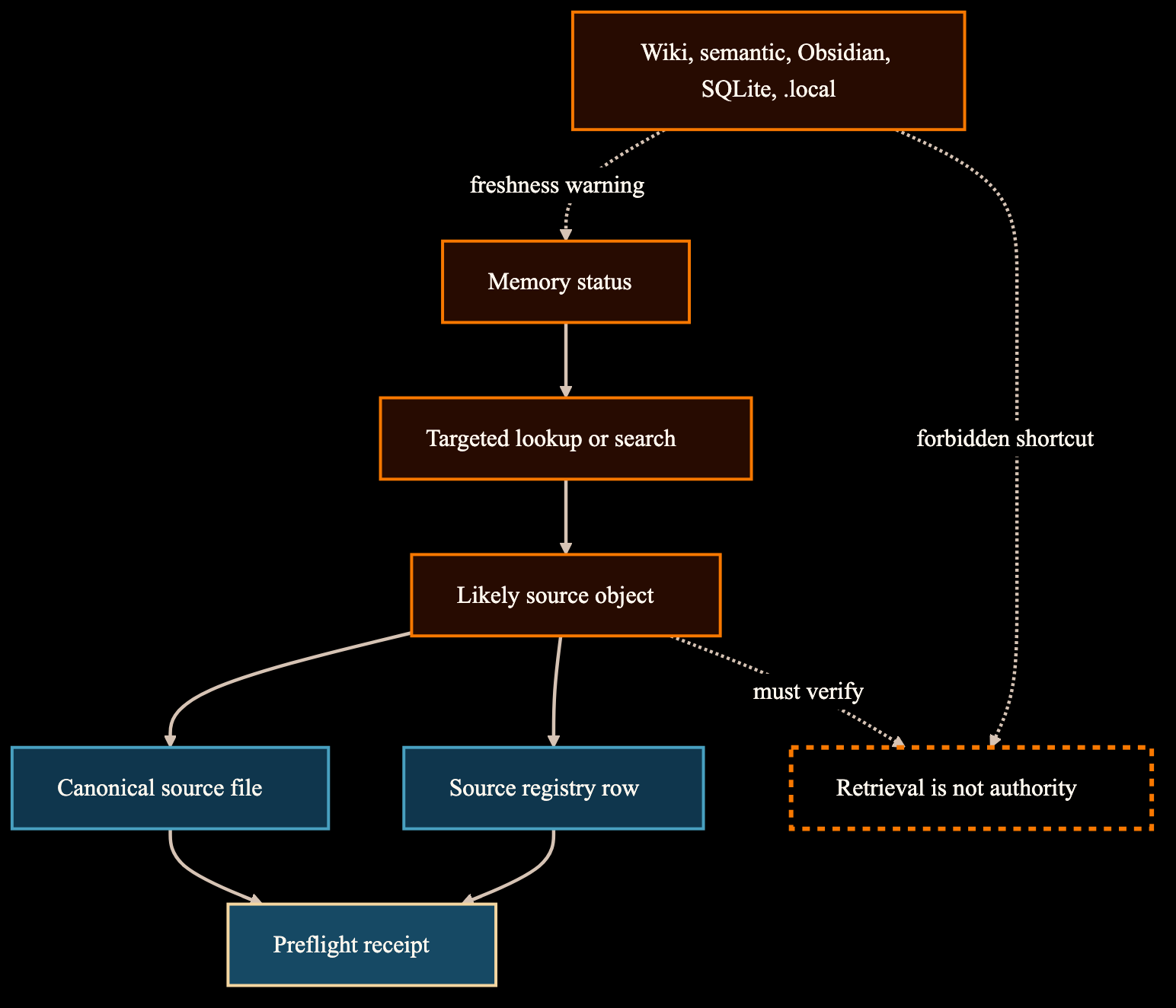
Retrieval layer classes
Navigation layers stay below source authority.
The route keeps local, generated, and indexed material useful without giving it source status.
| Layer | Examples | Use | Limit |
|---|---|---|---|
| Memory lookup | Local memory summaries, prior packet notes, and retrieved workflow hints. | Find candidate files, commands, and prior decisions quickly. | Memory lookup is a navigation aid, not claim authority. |
| Semantic extracts | Vector or text extracts used to locate related source objects. | Discover relevant source files or registries for inspection. | Extracts can omit context and cannot replace source reading. |
| Obsidian or wiki mirrors | Generated notes, object pages, and relationship mirrors. | Browse relationships and find source candidates. | Generated notes are retrieval layers unless promoted by a tracked source. |
| SQLite or local indexes | Local databases, source indexes, and cache tables. | Speed search and repeatable lookup across large source sets. | Index rows are not proof, source authority, or public publication state. |
| .local and QA caches | Ignored previews, screenshots, temporary analysis, and local artifacts. | Support local inspection, debugging, or browser QA. | .local data is not committed evidence or source authority. |
Source-first workflow
A retrieval hit becomes useful only after owner inspection.
The workflow separates discovery, source ownership, inspection, and uncertainty reporting.
| Step | Action | Boundary |
|---|---|---|
| Ask the retrieval question | Use memory, semantic search, wiki, or cache lookup to find candidate material. | The retrieval layer can suggest where to inspect; it cannot decide the claim. |
| Locate the owner | Map the hit to a source file, registry row, handoff, completion, PRD, or manifest. | The owner, not the retrieval hit, controls claim status. |
| Inspect the source | Read the current tracked source or governed record before changing public copy. | If source and retrieval disagree, source wins. |
| Report the uncertainty | Name stale, partial, or local-only retrieval evidence before reuse. | Uncertainty remains visible instead of being hidden behind a polished route. |
Common failure modes
The useful warning is specific, not vague.
Retrieval layers fail differently. Naming the failure mode makes the safer next step clear.
| Risk | Safe response | Blocked use |
|---|---|---|
| Stale memory | Refresh against tracked files or state before relying on the hit. | Do not present an older memory note as current source truth. |
| Partial extract | Open the full source and surrounding context. | Do not infer missing assumptions from the extract alone. |
| Local cache | Treat cache paths as private QA or navigation support. | Do not cite `.local` or ignored cache state as public evidence. |
| Generated mirror | Use the mirror to locate the canonical source or registry row. | Do not edit the mirror to change canonical claims. |
Related internal routes
Use retrieval with source, derivative, registry, publication, and library boundaries.
The internal route network keeps readers oriented before they open local or generated surfaces.
Derivatives
Generated Derivatives
Compare retrieval layers with generated reader surfaces.
Open routeAuthority
Source Authority
Read the authority ladder before using retrieval evidence.
Open routeRecords
Registries
Map retrieval hits to source, derivative, workflow, and claim-boundary rows.
Open routeMemory
Memory Preflight
Review the governed memory preflight workflow and its source-first boundary.
Open routeLibrary
Library
Use curated reading paths when retrieval would expose repository structure too early.
Open routePublication
Publication Process
Read how public pages convert source-bounded material into reader surfaces.
Open route